ARcenso es un paquete diseñado para facilitar el acceso a los datos de los Censos Nacionales de Población, Hogares y Viviendas de Argentina. Los datos se entregan en formatos estándar de R, compatibles tanto con R base como con el ecosistema Tidyverse.
Nota sobre disponibilidad: El paquete se encuentra en desarrollo activo. Actualmente, el repositorio contiene una selección de tablas históricas de 1970 y 1980. La cobertura de años y niveles geográficos se irá completando progresivamente.
Instalación y Carga
Puedes instalar la versión de desarrollo desde GitHub:
remotes::install_github("SoyAndrea/arcenso")Cargamos el paquete:
Consultar disponibilidad de datos
Previo a la descarga, es necesario identificar las tablas disponibles en el repositorio. El paquete ofrece dos métodos para realizar esta consulta:
Opción A: Explorador Interactivo (Recomendado)
Esta función ejecuta una aplicación Shiny integrada en el paquete. A través de su interfaz gráfica, es posible explorar el catálogo de datos, aplicar filtros y visualizar la información de manera dinámica.
Asimismo, permite copiar el identificador (ID) del cuadro seleccionado para utilizarlo posteriormente como argumento en las funciones de descarga.
Ejemplo:
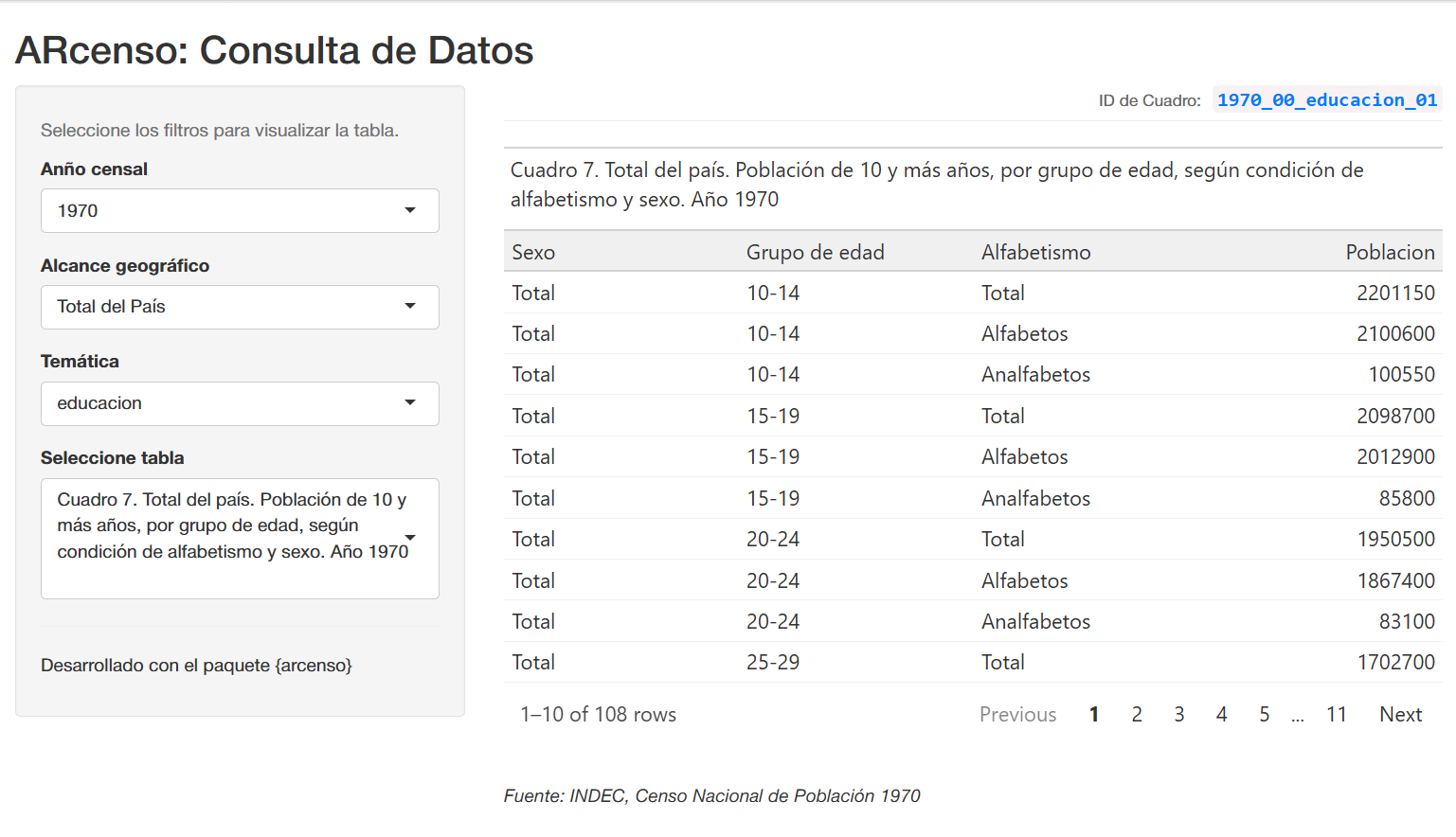
Como se observa en la interfaz, tras seleccionar los filtros (año, alcance y temática), el sistema muestra una previsualización de los datos.
Dato clave: En el margen superior derecho de la tabla se encuentra el ID de Cuadro (por ejemplo: 1970_00_educacion_01). Puede copiar este identificador para solicitar la tabla específica mediante código en el siguiente paso.
Opción B: Consulta vía Consola
Alternativamente, es posible consultar el catálogo directamente desde
la consola de R mediante la función check_repository().
Esta función devuelve un listado con los metadatos de las tablas que coinciden con los criterios de búsqueda. A continuación, se ejemplifica la consulta para el tópico migración en el año 1970:
# La función nos listará los IDs de cuadro, código geográfico y títulos disponibles
check_repository(
year = 1970,
topic = "migracion"
)
#> # A tibble: 3 × 3
#> id_cuadro cod_geo titulo
#> <chr> <chr> <chr>
#> 1 1970_00_migracion_01 00 Cuadro 2. Total del país. Población total, por g…
#> 2 1970_00_migracion_02 00 Cuadro 5. Total del país. Población total, por l…
#> 3 1970_00_migracion_03 00 Cuadro 6. Total del país. Población de 5 y más a…Descargar datos
Una vez identificada la información de interés, se utiliza la función
get_census().
Es importante destacar que esta función retorna invariablemente un objeto de tipo lista, el cual contiene uno o más data frames correspondientes a las tablas solicitadas.
Opción A: Usando R Base
No necesitas dependencias externas para usar arcenso.
# Descargamos
datos_censo <- get_census(
year = 1970,
topic = "migracion",
geo_code = "00"
)
# Extraemos la segunda tabla de la lista por su índice
tabla_migracion <- datos_censo[[2]]
# Vemos las primeras filas
head(tabla_migracion)
#> # A tibble: 6 × 3
#> lugar_residencia_habitual lugar_nacimiento poblacion
#> <chr> <chr> <chr>
#> 1 Total Total 23390050
#> 2 Total Total en el país 21179650
#> 3 Total Capital Federal 2946150
#> 4 Total Partidos del Gran Buenos Aires 1687600
#> 5 Total Resto de Buenos Aires 3418400
#> 6 Total Catamarca 257950Opción B: Usando Tidyverse
Si usas paquetes como dplyr, puedes integrar la descarga directamente en tu flujo de trabajo.
library(dplyr)
# Descargamos
datos_censo <- get_census(
year = 1970,
topic = "migracion",
geo_code = "00"
)
# Accedemos a la primera tabla de la lista y miramos su estructura
datos_censo[[2]] |>
glimpse()
#> Rows: 841
#> Columns: 3
#> $ lugar_residencia_habitual <chr> "Total", "Total", "Total", "Total", "Total",…
#> $ lugar_nacimiento <chr> "Total", "Total en el país", "Capital Federa…
#> $ poblacion <chr> "23390050", "21179650", "2946150", "1687600"…Opción C: Descarga directa por ID (Precisión máxima)
Si obtuviste un identificador específico (ej.
1970_00_educacion_01) desde la aplicación Shiny o mediante
check_repository(), puedes usarlo para descargar
únicamente esa tabla.
Esto es ideal para scripts reproducibles donde quieres asegurarte de estar trabajando siempre con el mismo cuadro.
# Descarga usando el ID específico del cuadro
tabla_educacion <- get_census(id = "1970_00_educacion_01")
# Inspeccionamos el resultado
tabla_educacion
#> # A tibble: 108 × 4
#> sexo grupo_de_edad alfabetismo poblacion
#> <chr> <chr> <chr> <chr>
#> 1 Total 10-14 Total 2201150
#> 2 Total 10-14 Alfabetos 2100600
#> 3 Total 10-14 Analfabetos 100550
#> 4 Total 15-19 Total 2098700
#> 5 Total 15-19 Alfabetos 2012900
#> 6 Total 15-19 Analfabetos 85800
#> 7 Total 20-24 Total 1950500
#> 8 Total 20-24 Alfabetos 1867400
#> 9 Total 20-24 Analfabetos 83100
#> 10 Total 25-29 Total 1702700
#> # ℹ 98 more rowsComunidad
Ahora que dispones de los datos, el siguiente paso es integrarlos en tus análisis.
Citación: Si utilizas ARcenso en investigaciones, publicaciones o proyectos, te invitamos a citar el paquete
citation("arcenso").Feedback: Las sugerencias, reportes de errores y contribuciones son bienvenidas. Para más información sobre cómo colaborar con el proyecto, consulta nuestra guía de contribución.